For the sixth video in the Design Yourself series the group worked with artist Erica Scourti. For the activity the participants used optical character recognition software (OCR) to generate poetry from their own handwriting and writing (leaflets, signage) found throughout the Barbican building.




The next stage in the workshop was going to be to take this extracted text and run it through a text to speech synthesizer, but unfortunately there wasn’t time to get to this stage.
One of the things I liked about the software they used was that it showed you the image of the text that it recognised and extracted, producing a kind of cut-and-paste poetry.
To make the sixth video I wanted to somehow utilize this OCR and text-to-speech process and make a video collage of words and synthesized speech. The challenge was finding a way to do this using only open source software. Finding open source OCR software that works on Linux is not a problem. After a while I discovered that Tesseract is the gold standard for OCR software and that most other software act as frontends or interfaces to it. Here’s a few examples:
- https://wiki.gnome.org/Apps/OCRFeeder
- https://danpla.github.io/dpscreenocr/
- http://www.tobias-elze.de/pdfsandwich/
- openpaperwork
- gscan2pdf
- ocrmypdf
However, they all output only the text, and not the image of the extracted text. I’m aware that my use case is quite specific so I don’t blame the developers for this.
Eventually I took to Twitter and Mastodon with my questions. _vade pointed to a bug report on Tesseract which showed that getting the coordinates of recognised words is possible in Tesseract. If I knew the coordinates of words then perhaps I could use that to extract the image of the word. However, doing it this way required using it’s C interface and learning C wasn’t feasible at the time.
After some further digging around Tesseract I found a bug report that makes reference to hOCR files:
hOCR is an open standard of data representation for formatted text obtained from optical character recognition (OCR). The definition encodes text, style, layout information, recognition confidence metrics and other information using Extensible Markup Language (XML) in the form of Hypertext Markup Language (HTML) or XHTML.
This file looked like it contained the coordinate data I needed, and obtaining such a file from Tesseract was as simple as running one command. The next task was finding a tool (or tools) to interpret hOCR files. Here’s a selection, which should really be added the the previous list to form a mega-list:
- https://github.com/z4y4ts/hocr-bboxes-viewer
- https://github.com/UB-Mannheim/ocr-gt-tools
- https://github.com/dmi3kno/hocr
- https://github.com/UglyToad/PdfPig
- https://github.com/tmbdev/hocr-tools
- https://github.com/manisandro/gImageReader
hocr-tools proved to be the most feature complete and stable. It runs on the command line, which opens it up for easy automation and combining with other programs. After reading the documentation I found a process for extracting the images of words and even making videos from each word/sentence with synthesized speech. Here’s how I did it:
Generate hOCR file
First I needed to generate a hOCR file using Tesseract. For the example I used the first page from the first chapter of No Logo by Naomi Klein.
tesseract book.jpg book hocr
This produced a file called book.hocr. If you look at the source code of the file you can see it contains the bounding box coordinates of each word and line.
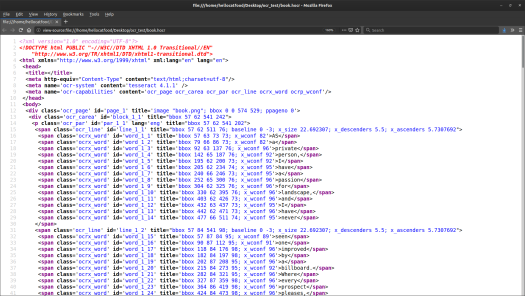
Extract images
Using the hOCR file I can extract images of the lines
hocr-extract-images -P 10 book.hocr
This generates both pngs of each line and also a corresponding text file containing the text
Text to speech
Using eSpeak I can generate a wav file of a synthesized voice reading each line.
for file in *.txt ; do espeak -z -f $file -w ${file%.*}.wav ; done
Make video clips
Finally, I needed to combine the png image of the text with the wav file of the synthesized speech into a video
for i in $(seq -f "%03g" 1 83) ; do ffmpeg -loop 1 -i line-$i.png -i line-$i.wav -c:v libx264 -tune stillimage -vf scale="width=ceil(iw/2)*2:height=ceil(ih/2)*2" -pix_fmt yuv420p -shortest -fflags +shortest ${i%.*}.mp4 -y ; done
I used fflags because without it the video was always adding a couple of seconds of silence.
By the end of this I had a folder full of lots of files.
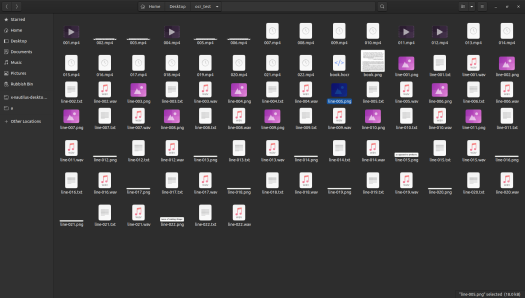
Voila!
The last part of this was to manually arrange the video clips into a video collage. I made this example video to demonstrate to the group what could be done.
Getting to this point took some time but with what I’ve learnt I can replicate this process quickly and simply. In the end the group decided no to use OCR to generate text and instead wrote something themselves. They did still use text-to-speech software and even filmed themselves miming to it. Here’s the finished video:
This was the last video I made for the Design Yourself project. I’ve written about techniques used to make older videos in past blog posts. Go read the Barbican website for more information on the project