From 16th March to 27th April I ran a four part Pure Data Patching Circle at Birmingham Open Media. It was originally intended to be an informal gathering of Pure Data and “creative coding” enthusiasts but quickly it turned into a course in using Pure Data. Here’s some of what I learnt from running it.
This was an almost exact replication of the beginner’s Pure Data workshops that I’ve done in the past at places such as GLI.TC/H 2012, Vivid Projects and Flip Festival. I first introduced some of the projects that I have done and then dove straight into things like installing the software on different platforms.
This part, in itself, had a couple of issues. The biggest problem is that Pure Data Extended, which is the most feature-complete version of Pure Data, is effectively dead. It hasn’t received an update in over two years and the developer seems to have abandoned any efforts to update it. Because of this I was a bit cautious in instructing people to install this software. However, after evaluating the situation, taking a chance on Pure Data Wxtended, which is still in use today despite its age, seemed a better option than downloading Pure Data Vanilla and manually compiling/installing all the necessary libraries. Maybe one day PD L2Ork will be cross platform (something which may be possible thanks to a graphical user interface (GUI) rewrite effort), and maybe the whole infrastructure of PD will become more mature. Until then, Pure Data Extended was suitable.
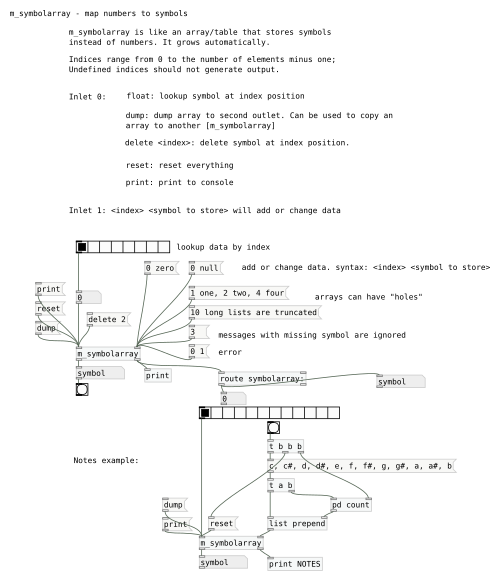
Following the installation the very basics were covered. I explained the difference between object boxes, GUI boxes, messages boxes etc, and how to change their properties. These are simple concepts but really important to using Pure Data. People that joined later in the patching circles still picked up a bit of this information, but spending a lot of time on it ensured they understood fully.
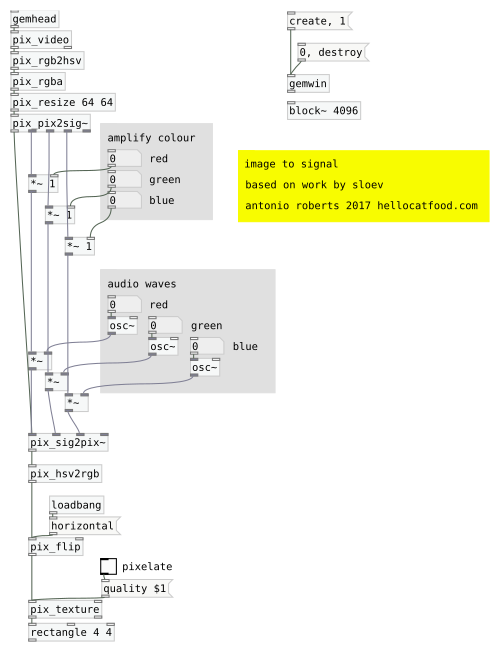
The workshop concluded how to use the amplitude of microphone input to control the scale of an object that had their webcam feed as a texture. Not a necessarily useful feature but a great way to introduce interactive visuals and the potential of Pure Data.
One thing I learnt from this first Patching Circle is that there isn’t a big enough community of creative coders in Birmingham and the surrounding area to support informal, peer led meetups. For that reason I devised a course plan for the following Patching Circles.
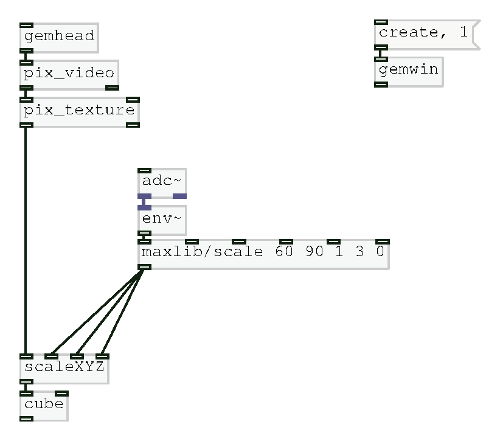
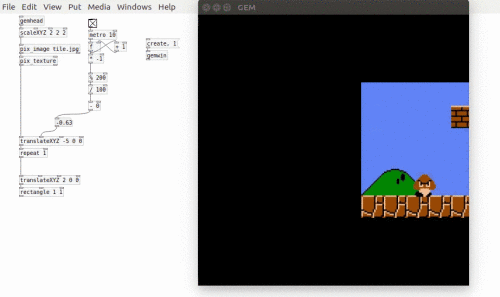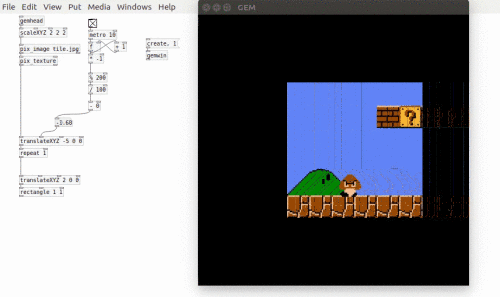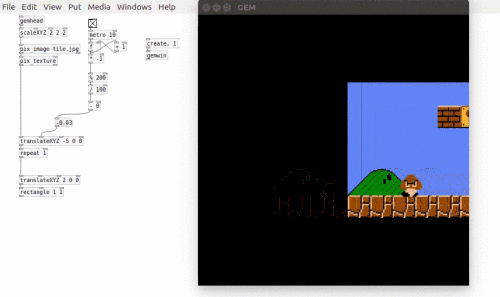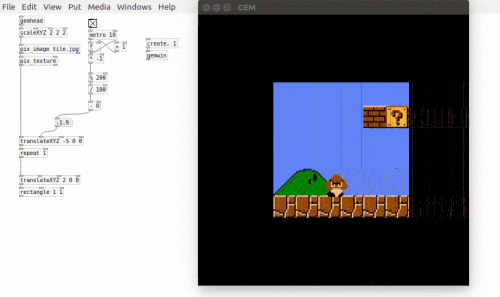
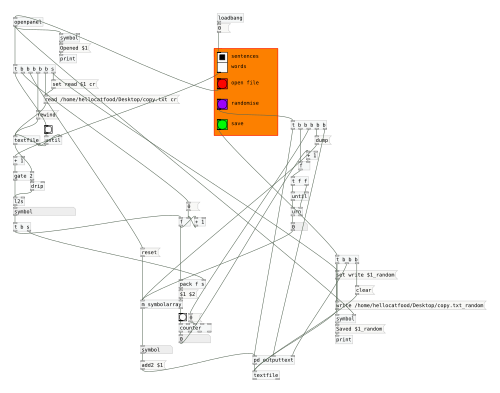
Following feedback from the first Patching Circle I took a more structured approach to this Patching Circle. This was definitely the right approach as the topic, loading and using video, can be a difficult one to grasp and so needed a structured way to teach it. Loading videos is a surprisingly long-winded task. One point I emphasised is that in Pure Data nothing is assumed. For example, just because a [gemwin] has been created it doesn’t mean that it automatically renders its graphics. the [1( messages needs to be sent to it. Similarly, when working with video in Pure Data, even though a video is loaded it will not automatically play – that requires the [auto 1( message. Also, there is no direct function to loop a video. Instead a user would tell the [pix_film] object to go back to the first frame when it has finished playing all the frames. Yes, this is looping, but there is no simple [loop 1( message. Finally, being able to control the speed would require the user to manually advance frames and specify at what speed to advance to the next frame. This brings in the problem of knowing how many frames are in a video. A solution to this is shown below.
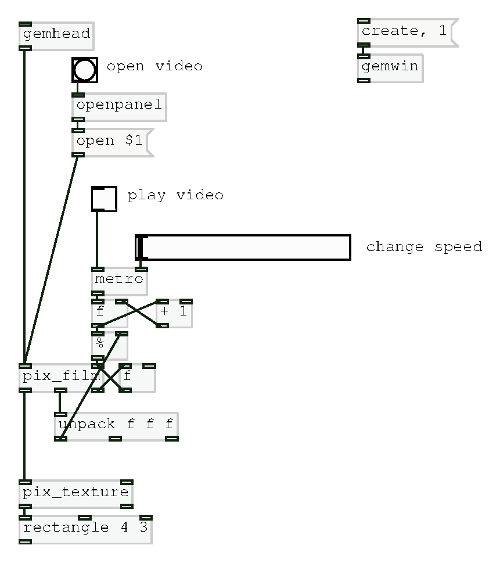
We concluded the patching circle by learning how to add in custom controls using the [key] command. Having GUI boxes such as [tgl], [bng] etc allows a user to interface with the patch by using their mouse. However, in a live performance being quick to react is important and that’s where the limitations of the mouse are shown. Using [key] a user can map any key on their keyboard to anything in Pure Data. For example, k could trigger the [pix_kaleidoscope] effect and pressing the arrow keys could speed up or slow down video. Doing this is simple and requires just knowing which key is represented by which number.
With all this knowledge the participants learnt how to build a very simple video mixer.
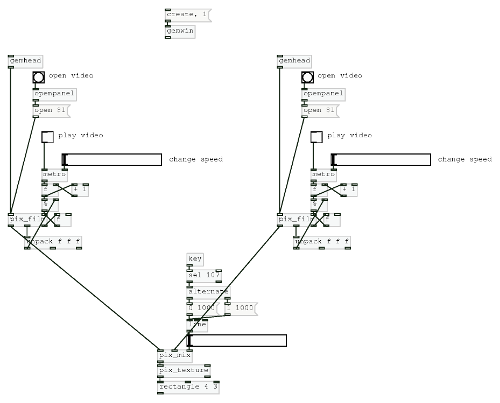
objects covered
[pix_film], [f]/[float], [key], [sel], [line], [pix_contrast], [pix_kaleidoscope] etc, [maxlib/scale], [tgl]
Just like in typed programming languages, the appearance, layout and quality of Pure Data patches is just as important as whether it works. Similarly, learning how to reuse code makes patching more efficient and provides some future proofing. For the third patching circle I took a break from teaching interactivity to focus on creating interfaces, subpatches and abstractions.
The benefits of subpatches were quite easy to show. I gave the task to the participants to encapsulate all of the objects that they used to make a video player into one subpatch that they could easily reuse.
Moving on from this I asked them to build a single-button interface for it that would simply load a video and automatically play and loop it. Creating an interface for a patch is useful for two reasons: It allows you to easily navigate you patch and it can provide valuable feedback on what is happening. Unfortunately, using Graph-on-Parent and [canvas] objects to create interfaces is a somewhat tricky.
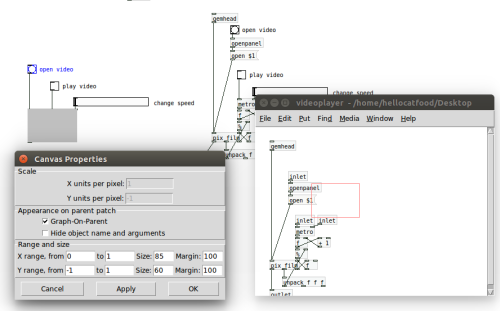
The red box that shows what will be shown on the parent patch is not easily configurable. Yes, you can specify its dimensions and position, but being able to do it using resize handles would make this process a lot easier. The same applies to [canvas] objects. What we found is that even if an object is just a few pixels over the red line it will not show in the parent patch. Finally, and perhaps most annoyingly, the Z order of the objects cannot be changed. Instead, this is determined upon creation of the object, meaning if a user wants to have a [canvas] object behind their objects they either have to create it before everything else or cut and paste everything so that it’s restacked. Yes, quite annoying.
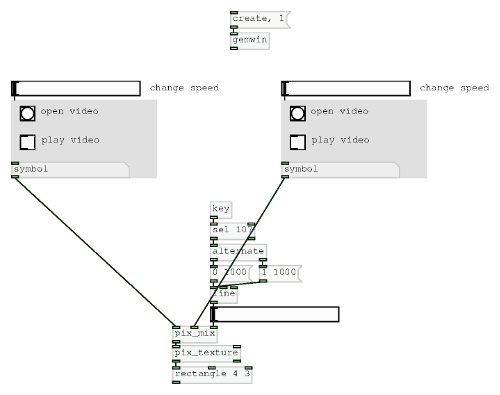
Objects covered
[pd], [inlet], [outlet], [inlet~], [outlet~], comment, [$0]
So far I had covered everthing that most regular VJ software can already do: play video files and add effects to them. Although not alone in this feature, Pure Data allows you to create complex patterns from its array of simple 3D shapes or your own models. By learning how to use [repeat] you can turn a simple [cube] object into an array of cubes that dance around. The last Patching Cirlce was perhaps the most difficult, even for myself, but I felt it shows best what Pure Data is capable of.
To explain how the [repeat] object works I showed the participants the Magnetophon video I made with Axel Debeul from databit.me in 2013
Despite their being an array of cubes on screen only one [cube] object is used. I [repeat]ed the [cube] a number of times, [translateXYZ]‘d it along the X axes and [rotateXYZ]‘d it then [repeat]ed it some more and [translateXYZ]‘d it along the Y axis. Doesn’t make sense? Perhaps this patch will help:
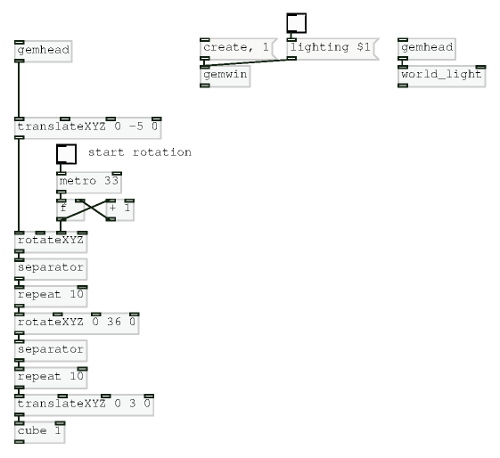
What I had trouble explaining was how the [separator] object worked. My understanding is that it is similar to pushMatrix and popMatrix from Processing. Perhaps it is, and perhaps I still don’t fully understand how it works yet, but it didn’t work as I expected it to. Nonetheless, I gave the participants the task of recreating the stack of cubes and most of them succeeded. Even those that didn’t made some really interesting patterns.
Objects covered
[repeat], [draw (, [model], [multimodel], [separator]
Summary
Teaching a four-part course was an eye opener for me. It showed me that to really learn Pure Data you ned more than an introductory session. It also emphasised to me that face0to-face tuition is really beneficial to some people and probably would have helped me learn better in my early days of using Pure Data. Of course, if you want me to lead a beginner’s session or a more advance one just get in touch.